
Dev Blog
Inference time benchmark comparison between CIANNA, TensorFlow and PyTorch for two architectures (LeNet5, darknet19).
[Up to date with V-1.0.0.0 release]
Configuration: Free Google Colab environment from June 2025, using an Nvidia T4 GPU (Turing, 2560 Cuda cores, 16 GB RAM, peak FP32: 8.141 TFLOPS, and FP16: 65.13 TFLOPS). The used versions of each framework are: CIANNA 1.0 (Cuda 12.5), TensorFlow 2.71 (Cuda 12.5), PyTorch 2.6.0 (Cuda 12.4). All networks are evaluated for inference only, but most observations remain valid for training. Network architectures and notebooks are provided at the end of the page.
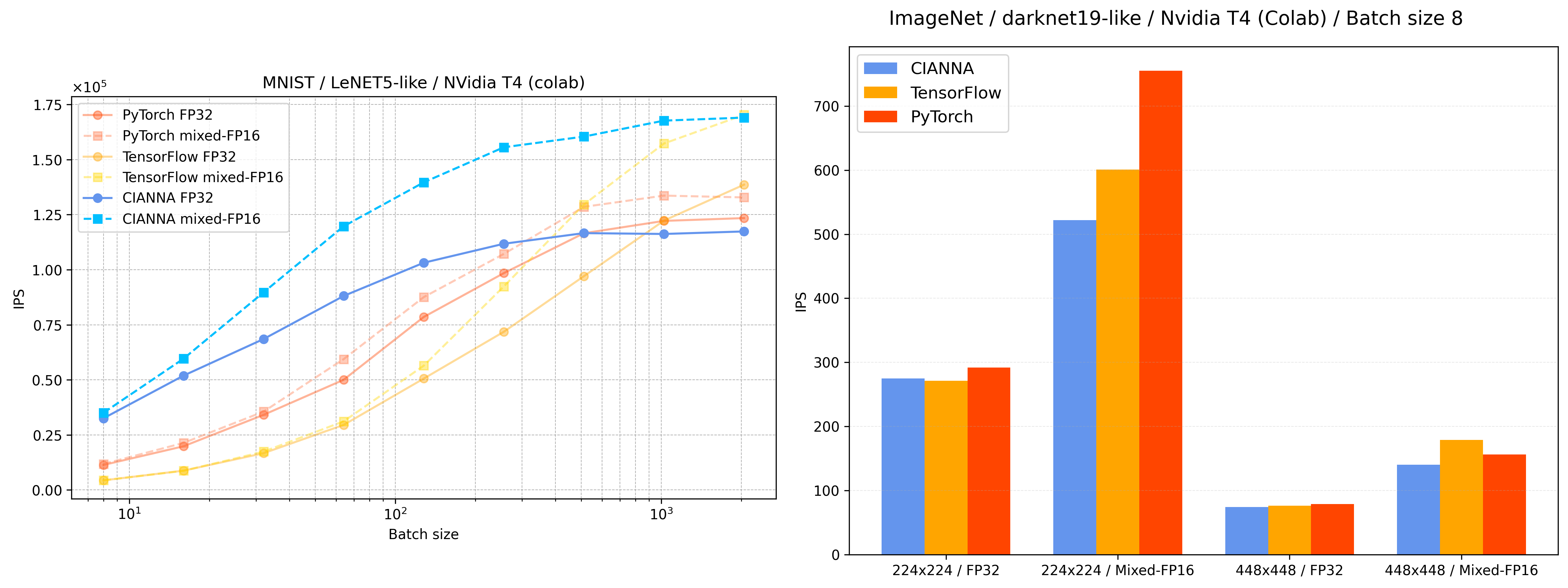
Run on MNIST with input size of 28x28.
cnn.conv(f_size=i_ar([5,5]), nb_filters=8 , padding=i_ar([2,2]), activation="RELU")
cnn.pool(p_size=i_ar([2,2]), p_type="MAX")
cnn.conv(f_size=i_ar([5,5]), nb_filters=16, padding=i_ar([2,2]), activation="RELU")
cnn.pool(p_size=i_ar([2,2]), p_type="MAX")
cnn.dense(nb_neurons=256, activation="RELU", drop_rate=0.5)
cnn.dense(nb_neurons=128, activation="RELU", drop_rate=0.2)
cnn.dense(nb_neurons=10, strict_size=1, activation="SMAX")
Run on ImageNet with input size of 224x224 or 448x448.
cnn.conv(f_size=i_ar([3,3]), nb_filters=32 , padding=i_ar([1,1]), activation="RELU")
cnn.norm(group_size=4)
cnn.pool(p_size=i_ar([2,2]), p_type="MAX")
cnn.conv(f_size=i_ar([3,3]), nb_filters=64 , padding=i_ar([1,1]), activation="RELU")
cnn.norm(group_size=8)
cnn.pool(p_size=i_ar([2,2]), p_type="MAX")
cnn.conv(f_size=i_ar([3,3]), nb_filters=128 , padding=i_ar([1,1]), activation="RELU")
cnn.norm(group_size=8)
cnn.conv(f_size=i_ar([1,1]), nb_filters=64 , padding=i_ar([0,0]), activation="RELU")
cnn.norm(group_size=8)
cnn.conv(f_size=i_ar([3,3]), nb_filters=128 , padding=i_ar([1,1]), activation="RELU")
cnn.norm(group_size=8)
cnn.pool(p_size=i_ar([2,2]), p_type="MAX")
cnn.conv(f_size=i_ar([3,3]), nb_filters=256 , padding=i_ar([1,1]), activation="RELU")
cnn.norm(group_size=16)
cnn.conv(f_size=i_ar([1,1]), nb_filters=128 , padding=i_ar([0,0]), activation="RELU")
cnn.norm(group_size=16)
cnn.conv(f_size=i_ar([3,3]), nb_filters=256 , padding=i_ar([1,1]), activation="RELU")
cnn.norm(group_size=16)
cnn.pool(p_size=i_ar([2,2]), p_type="MAX")
cnn.conv(f_size=i_ar([3,3]), nb_filters=512 , padding=i_ar([1,1]), activation="RELU")
cnn.norm(group_size=16)
cnn.conv(f_size=i_ar([1,1]), nb_filters=256 , padding=i_ar([0,0]), activation="RELU")
cnn.norm(group_size=16)
cnn.conv(f_size=i_ar([3,3]), nb_filters=512 , padding=i_ar([1,1]), activation="RELU")
cnn.norm(group_size=16)
cnn.conv(f_size=i_ar([1,1]), nb_filters=256 , padding=i_ar([0,0]), activation="RELU")
cnn.norm(group_size=16)
cnn.conv(f_size=i_ar([3,3]), nb_filters=512 , padding=i_ar([1,1]), activation="RELU")
cnn.norm(group_size=16)
cnn.pool(p_size=i_ar([2,2]), p_type="MAX")
cnn.conv(f_size=i_ar([3,3]), nb_filters=1024, padding=i_ar([1,1]), activation="RELU")
cnn.norm(group_size=32)
cnn.conv(f_size=i_ar([1,1]), nb_filters=512 , padding=i_ar([0,0]), activation="RELU")
cnn.norm(group_size=16)
cnn.conv(f_size=i_ar([3,3]), nb_filters=1024, padding=i_ar([1,1]), activation="RELU")
cnn.norm(group_size=32)
cnn.conv(f_size=i_ar([1,1]), nb_filters=512 , padding=i_ar([0,0]), activation="RELU")
cnn.norm(group_size=16)
cnn.conv(f_size=i_ar([3,3]), nb_filters=1024, padding=i_ar([1,1]), activation="RELU")
cnn.norm(group_size=32)
cnn.conv(f_size=i_ar([1,1]), nb_filters=nb_class , padding=i_ar([0,0]), activation="LIN")
cnn.pool(p_size=i_ar([1,1]), p_type="AVG", p_global=1, activation="SMAX")